One of the simplest way to “encrypt” a piece of English text is the Caesar (rotational) cipher which shifts each letter by a fixed number of places in the alphabet with wrap around. A well-known example is rot13 where every letter is shifted by 13 places. So A -> N, B -> O and so on.
I have often read that simple ciphers like this can be broken by “frequency analysis”, taking advantage of the observation that the frequencies of the various letters in English is well-known. But what exactly does that mean? How would such frequency analysis actually work?
First, let’s write some code to encrypt and decrypt. For simplicity we’ll restrict our alphabet to just the uppercase letters A-Z and space and we’ll leave the space characters unchanged. The “key” for our encryption is a single number in the range [0, 25].
def rotate(c: str, n: int) ->str:""" Rotate the character c by n places, wrapping around. c must be an uppercase letter """assertord("A") <=ord(c) <=ord("Z") or c ==" "match c:case" ":return ccase _:returnchr((ord(c) -ord("A") + n) %26+ord("A"))def caesar_encrypt(s: str, n: int) ->str:return"".join([rotate(c, n) for c in s])def caesar_decrypt(s: str, n: int) ->str:return"".join([rotate(c, -n) for c in s])caesar_encrypt("THE MYSTIC CHORDS OF MEMORY", 13)
'GUR ZLFGVP PUBEQF BS ZRZBEL'
Our task now is to figure out the key n when given only the encrypted text and the knowledge that a Caesar cipher has been used.
Since we want to do frequency analysis in some fashion, let’s write a function to return the letter frequencies for a piece of text. For reasons that will become clear later we’ll actually compute a probability mass function, which is just the frequencies divided by the total count of letters. We will represent the PMF as a dictionary that maps each letter of our alphabet to its probability.
from collections import CounterLetterPmf =dict[str, float]def letter_pmf(s: str) -> LetterPmf: s = s.upper() counts = Counter(s) total =sum(counts.values())return {c: counts[c] / total for c in counts.keys()}letter_pmf("So we beat on boats against the current"+"borne back ceaselessly into the past")
A reasonable way to use letter frequencies to break the cipher is:
Try every value for the key (0-25) and decrypt the given ciphertext.
Pick the plaintext whose letter frequencies most closely match that of general English text.
(Ofcourse we could argue that this is all needlessly complicated. If we already know that the text has been encrypted with a Caesar cipher, we can just inspect the results of trying all 26 keys and surely all but one of them will look like gibberish. That’s true, but in this post we’re more interested in teaching a computer to do that work for us.)
Let’s use the complete Sherlock Holmes canon as a stand-in for the English language as a whole and compute the letter PMF.
def clean_text(s: str) ->str:return"".join([c for c in s if c.isalpha() or c ==" "]).upper()HOLMES = letter_pmf(clean_text(open("data/holmes.txt").read()))
For a moment let’s assume we have a way to measure how close two frequency distributions are and call it pmf_distance. The definition below is just a dummy, always returning 0.0.
import mathimport numpy as npdef all_distances(cipher: str) -> np.array:""" Return the PMF distances between the decrypted text and English (HOLMES) for each of the keys in the range 0-25 (inclusive). """return np.array([ pmf_distance( letter_pmf(caesar_decrypt(cipher, key)), HOLMES )for key inrange(0, 26) ])def try_decrypt(cipher: str) -> (int, str):""" Return the key and decrypted text, choosing the key that yields the smallest PMF distance to English. """ correct_key = np.argmin(all_distances(cipher))return correct_key, caesar_decrypt(cipher, correct_key)SECRET = ("ZV DL ILHA VU IVHAZ HNHPUZA AOL JBYYLUA IVYUL IHJR "+"JLHZLSLZZSF PUAV AOL WHZA")try_decrypt(SECRET)[1]
'ZV DL ILHA VU IVHAZ HNHPUZA AOL JBYYLUA IVYUL IHJR JLHZLSLZZSF PUAV AOL WHZA'
This doesn’t get us anywhere ofcourse because we haven’t figured out what a good pmf_distance should be.
Relative entropy
The Shannon information content of an event \(x\) with probability \(P(x)\) is defined as \(log(1 / P(x))\). This captures the intuition that the information obtainable from an event is proportional to how surprising it is. If you have a dog that barks at everything it’s not a very good guard dog because the bark tells you nothing and thus has low information content.
The entropy of a probability distribution is the sum of the information content of its events, weighted by the probability of each event.
This too makes intuitive sense. For example, imagine a light that can be in two states on or off with equal probability. The entropy of this distribution is:
0.5* math.log2(1/0.5) +0.5* math.log2(1/0.5)
1.0
In other words, the state of the light gives you 1 bit of information.
The relative entropy of a distribution \(P(x)\) compared to another distribution \(Q(x)\) captures some notion of the extra information we get from \(P\). Unfortunately the intuitive derivation of this is not at all clear to me so we’ll just have to trust the textbooks. The relative entropy is defined as:
def relative_entropy(p: LetterPmf, q: LetterPmf) ->float:returnsum(p[x] * (math.log2(p[x]) - math.log2(q[x])) for x in p.keys())
We can also think of this as an informal kind of “distance” between \(P\) and \(Q\), while remembering that it’s not a true distance in the mathematical sense because it’s not symmetric (\(D(P, Q) \neq D(Q, P)\) in general) and it doesn’t satisfy a few other distance-like properties. This distance is also known as the Kullback-Leibler divergence, a name that tells you nothing while being needlessly scary-looking.
We can try the decryption again, this time using the relative entropy as the distance between the distribution for each attempted decryption and the distribution for the English language:
'SO WE BEAT ON BOATS AGAINST THE CURRENT BORNE BACK CEASELESSLY INTO THE PAST'
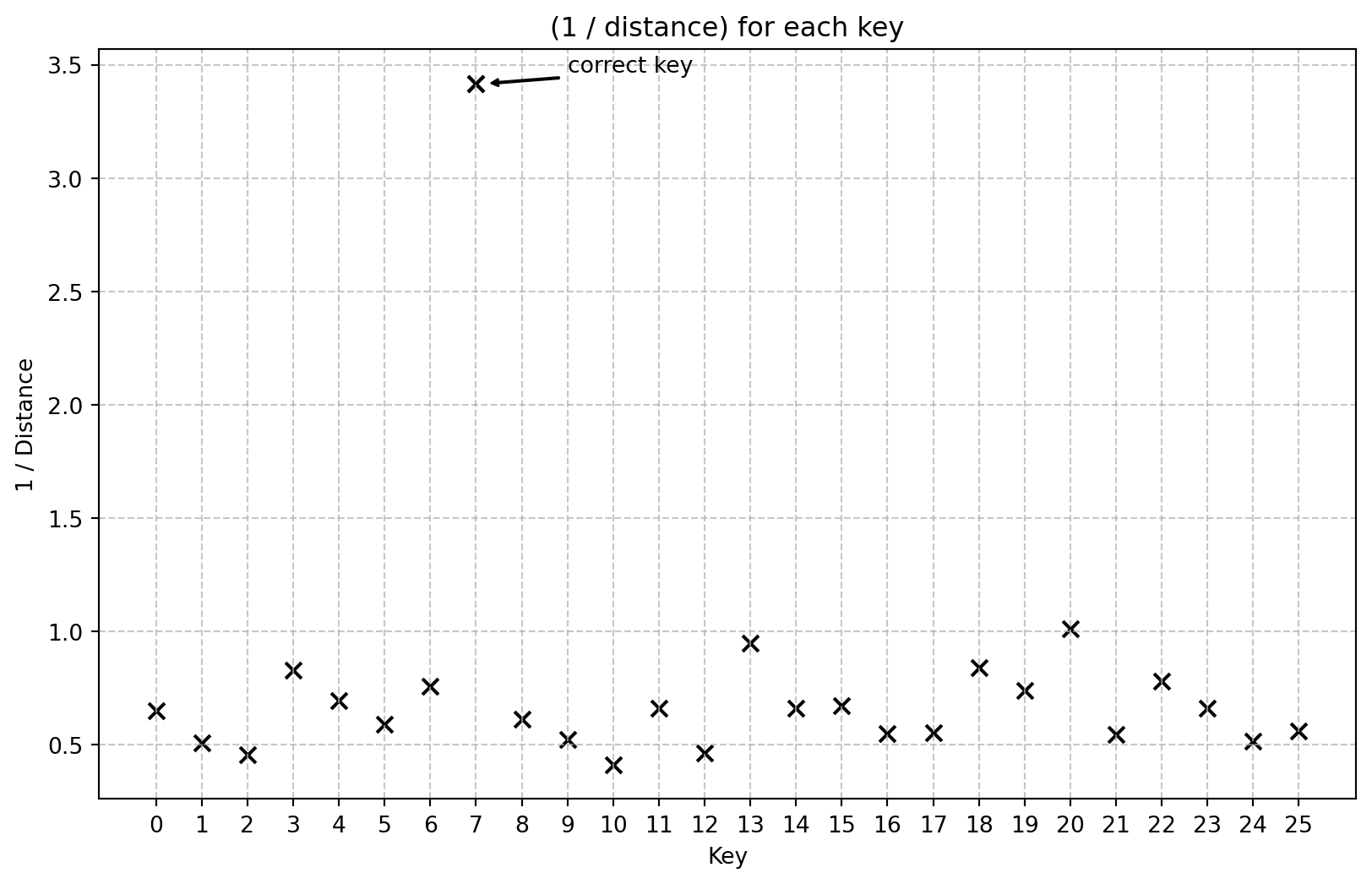
We can also visualize the relative entropy for each of the candidate keys to get a sense of how the frequency distribution with the correct key is so obviously different from that for all the wrong keys. We’ll plot the reciprocal of the distance just to make the graph prettier.